How TaxBandits API Ensures Uninterrupted Service, Zero Downtime, and a Seamless Tax Season


Imagine it’s the day before a major tax deadline—you’re racing against the clock to submit your forms. Every second counts. But what happens if your system can’t keep up? What if it crashes when the traffic spikes, and you’re left scrambling to recover?
At TaxBandits, we don’t let that happen!
We've built our API to be resilient, scalable, and unstoppable. We’re not just thinking about uptime as a checkbox—this is about creating a system that can handle whatever life throws at it, whether it’s an influx of filings or a new version of the platform going live. And, we’re doing it in a way that’s seamless, automatic, and invisible to you.
In this blog, we'll take you through the technical innovations and practices behind the TaxBandits API architecture, demonstrating how we deliver consistently reliable performance. We’ll show how our system can respond to changes in load, ensure zero downtime during updates, and handle traffic with precision.
Kubernetes-Based Deployment: The Backbone of Our System
We deploy all components of our public API using Kubernetes, the leading platform for container orchestration.
Kubernetes offers unmatched flexibility and efficiency in managing microservices at scale, and here’s why we chose it:
-
Implement Advanced AI-Driven Features: Kubernetes’ flexibility allows us to experiment with and deploy cutting-edge technologies, like AI and machine learning, to enhance user experiences, predict filing trends, and automate workflows.
-
High Availability: The architecture of Kubernetes is designed for resilience. Pods are spread across multiple nodes within the cluster, so if one node fails, others can immediately pick up the slack. This distributed nature minimizes the risk of downtime.
-
Self-Healing: One of the most powerful features of Kubernetes is its ability to self-heal. If a pod crashes or becomes unresponsive, Kubernetes automatically restarts or replaces it. This means that when your users are depending on TaxBandits, we’re always on, even when things go wrong behind the scenes.
Think of Kubernetes as a system that ensures our API never blinks, even during periods of high demand.
Optimizing Resources with Karpenter: Scalability Meets Efficiency
While Kubernetes manages our containers, Karpenter optimizes the resources themselves by scaling our nodes based on demand. Here’s how it works:
-
Dynamic Node Scaling: Karpenter automatically provisions new EC2 instances when the demand from the running pods exceeds the current capacity. Similarly, it removes underutilized nodes during quieter periods. This automatic scaling ensures that our infrastructure is always right-sized—helping us avoid both over-provisioning (which can lead to unnecessary costs) and under-provisioning (which can result in slowdowns or failures).
-
Cost-Efficiency: By continuously optimizing node usage, Karpenter helps us keep costs in check without sacrificing performance. It ensures that we are only using the resources we need, when we need them.
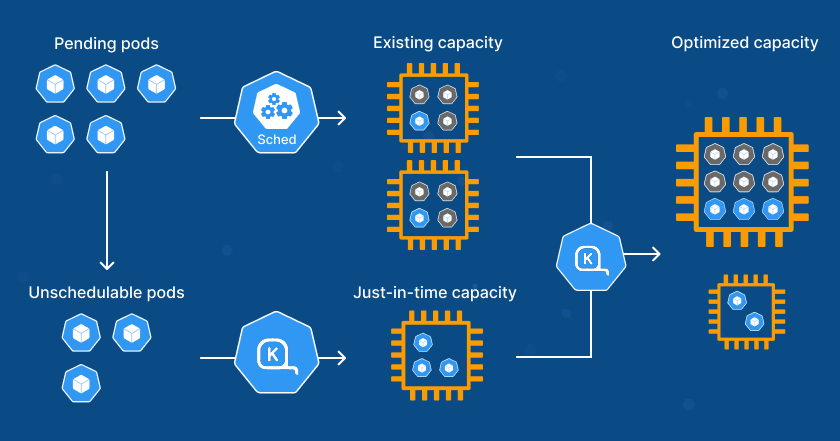
Take a tax season rush, for instance. Karpenter ensures that, as traffic spikes, new instances are spun up quickly to support the surge. But as soon as things settle, Karpenter reduces our resource footprint, keeping costs minimal.
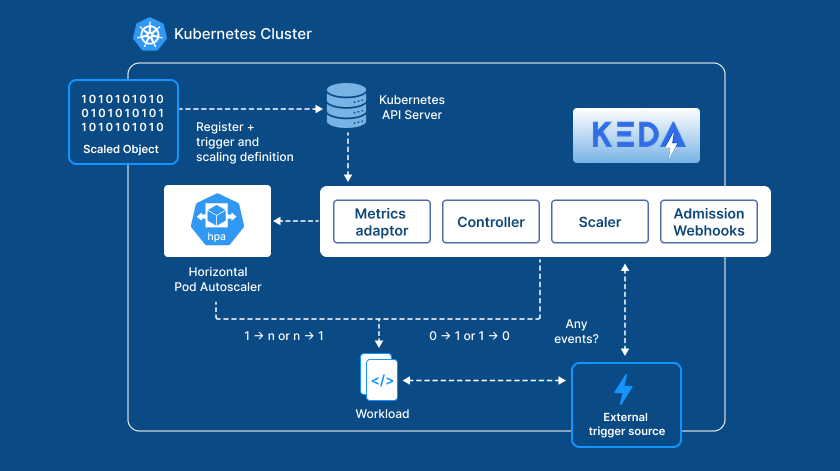
Event-Driven Scaling with KEDA: Keeping Performance in Check
Managing dynamic load requires more than just scaling pods based on traffic. That’s where KEDA (Kubernetes Event-Driven Autoscaler) comes into play.
-
Event-Driven Autoscaling: Unlike traditional scaling methods that depend on simple traffic metrics, KEDA allows our system to scale based on event-driven metrics. This could be anything from the length of a message queue in Kafka to the number of incoming requests being processed by our API. By responding to real-time signals, KEDA ensures that we scale efficiently during spikes in demand, without overshooting or wasting resources.
-
Seamless Integration: KEDA works hand-in-hand with Horizontal Pod Autoscaler (HPA) to ensure that pods are scaled to the optimal number based on load, ensuring that we only use the resources necessary to handle incoming requests efficiently.
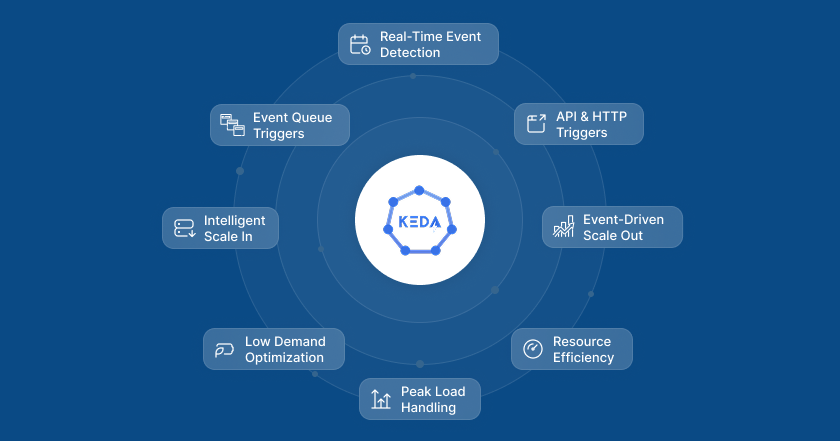
For example, when a major IRS deadline nears and filing volume increases, KEDA dynamically adjusts the number of active pods based on incoming requests. It ensures that your filings aren’t delayed, and it does this without any manual intervention.
Managing Traffic with Istio: Precision at Every Layer
To keep everything running smoothly, we rely on Istio, a powerful service mesh that helps us manage service-to-service communication and traffic flow. With Istio, we get:
-
Round-Robin Load Balancing: Istio evenly distributes incoming requests across available pods, ensuring no single pod is overwhelmed. When traffic spikes, the load is automatically shared, preventing bottlenecks and maintaining optimal performance.
-
Traffic Observability: Istio gives us deep visibility into how requests are flowing through our system, offering real-time monitoring, logs, and traces. This enables us to quickly identify issues, whether it's a slow pod or a misconfigured service, and address them before they impact your experience.
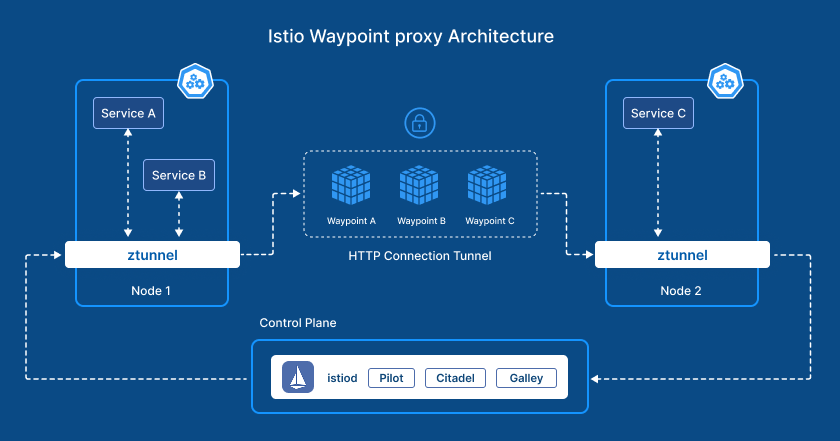
For example, during peak filing periods, if one pod starts lagging due to unexpected traffic, Istio ensures that the remaining pods share the load, allowing the system to handle the extra traffic smoothly.
Zero-Downtime Deployments: Updating Without Impact
Deploying new code and features is essential, but it should never come at the cost of downtime. That’s why we’ve adopted a rolling update mechanism for all new deployments:
-
Rolling Updates: When a new release is ready, Kubernetes launches new pods with the updated version of the API. However, these new pods aren’t exposed to incoming traffic until they are fully ready and healthy. Once verified, the old pods are gradually replaced, ensuring that the service remains available throughout the update.
-
Continuous Availability: Even while updates are happening in the background, your users never experience downtime. The system seamlessly transitions to the new version without a hiccup.
Think of it like upgrading the engines of an airplane mid-flight—carefully and without disrupting the journey. Users will never know the difference, but the system’s capabilities are always improving.
How We Handle Scheduled Maintenance: Predictability with Clarity
When we talk about “zero‑downtime deployments,” we’re describing how we engineer our architecture for updates without interruption. But let’s be clear: even the most robust systems need scheduled maintenance. That’s why we’ve paired our deployment strategy with a clearly-defined TaxBandits API Downtime Policy, so you know exactly what to expect.
-
Scheduled downtime is typically planned for Mondays between 1 AM - 3 AM ET. This downtime is predictable and infrequent, designed to accommodate tax-year updates, major architecture changes, and other necessary maintenance tasks. You’ll always receive advance notice via email, so you can be prepared—unless there’s an unforeseen requirement.
-
We commit to providing clear communication and coordinating these maintenance windows to minimize any impact on your workflow or integration.
-
Our infrastructure—powered by self‑healing pods, rolling updates, automated traffic management—means even during maintenance, the visible disruption to you is negligible. In many cases, you won't notice anything changing.
-
We also keep you informed with real-time status updates through our system status portal, where you can view uptime and maintenance details.
While our aim is to provide continuous availability, having a transparent downtime policy gives you predictability and ensures you’re always in the loop. For tax-related services where timing is critical, this level of clarity is key to keeping everything running smoothly.
Pod Health Monitoring: Keeping Everything Running Smoothly
A robust system is only as good as its ability to monitor and react to failures. To ensure that only healthy pods handle requests, we’ve implemented three types of Kubernetes health probes:
-
Startup Probe: This ensures that the application inside the pod is up and running before traffic is routed to it. If the pod hasn’t initialized correctly, Kubernetes holds off on sending any traffic.
-
Readiness Probe: This checks if a pod is ready to serve requests. If it’s not, Kubernetes reroutes traffic to other healthy pods until the one in question is ready.
-
Liveness Probe: This detects if a pod is running but no longer responsive. If a pod stops responding, Kubernetes will restart it automatically, restoring the service without manual intervention.
By continuously monitoring the health of each pod and making automated corrections, we ensure that only fully operational services are handling user requests.
How TaxBandits Ensures Continuity During External Service Outages
While TaxBandits has been designed for resilience and uptime, it's important to acknowledge that no system is entirely immune to disruptions—especially when relying on third-party services like cloud providers (e.g., AWS).
In the event of an outage from a service provider like AWS, here’s how TaxBandits ensures continuity and minimizes any impact on our API:
-
Multi-AZ (Availability Zone) Strategy: Ensuring Redundancy and Failover
We leverage the robust infrastructure of AWS by distributing our services across multiple Availability Zones (AZs) within a region. In the case of an AZ outage, our systems automatically failover to a different, healthy AZ without requiring manual intervention.
-
Cross-Region Disaster Recovery: Staying Ahead of the Unexpected
In addition to multi-AZ redundancy, we implement cross-region disaster recovery. This means that in the rare case of a larger regional AWS outage, our system can automatically switch to a backup region to maintain functionality. This further strengthens the resilience of the TaxBandits API, making sure that a service disruption in one region does not cause a full-blown outage.
-
Auto-Scaling with Karpenter and Kubernetes: Adapting to Demand
Even during an outage, our auto-scaling mechanisms, powered by Karpenter and Kubernetes, adjust the infrastructure dynamically. If there is an issue with a cloud provider, the system detects this and adjusts resources to accommodate the failover process. By maintaining automated scaling and resource optimization, we prevent resource shortages or slowdowns from affecting your experience.
-
Clear Communication: Keeping You in the Loop
In the rare event of an issue affecting our service, TaxBandits provides clear and timely communication. Through our system status portal and email notifications, we keep users informed about the issue, what’s being done to fix it, and when the service is expected to be fully restored.
The Bottom Line
At TaxBandits, we don’t just aim to keep the lights on—we’ve invested in building an uninterrupted, scalable, and secure system from the ground up.
It's not just about handling more users or more traffic; it’s about creating an infrastructure that’s ready for the unexpected, that adapts to change without missing a beat, and that lets you keep your business moving forward, no matter what.
When you can count on an API that works seamlessly behind the scenes—when your workflow remains smooth, whether it’s a quiet day or the busiest season—you can breathe easy. You can focus on growing your business, not worrying about tech hiccups.